
Unifying the Software Toolchain
The Tar Pit
Dealing with all the implicit state in the filesys and environment is probably going to be key to eventually making build systems not suck.
— John Carmack (@ID_AA_Carmack) January 2, 2015
The toolchain that we use to write software is fundamentally broken. Setting up the system environment in which we develop programs is challenging, even for expert programmers (imagine how a novice feels). Each programming language has its own package management and build system, which unsurprisingly vary widely in quality. Build reproducability is almost never guaranteed due to the implicit dependency on global system state. Package managers sometimes cannot even handle dependencies on multiple versions of the same library! Dependincies take on a nebulous quality - if an author removes their library from the centralized repository, suddenly any projects with a dependency instantly breaks. We saw this exact situation happen in 2016 after left-pad was removed from NPM. The implicit system state situation is so bad that I’ve worked on projects where the solution was to build a virtual machine image on a per project basis. Any new developer to the project would simply use the project virtual machine image as a starting point for development. This is a symptom that something is very, very wrong. We shouldn’t have to copy the entire machine just to acheive build reproducability.
But there is a problem even bigger than the package management problem. Each language that we develop has its own walled garden library ecosystem. As a concrete example, let’s examine the situation for graph theory libraries (which I often use in programming language related work). Python has its own graph theory library called NetworkX, C# has QuickGraph, and Haskell has algebraic-graphs. None of these graph theory libraries are related in any way, but fundamentally they implement and share the exact same algorithms. The amount of duplicated effort is massive! This also prevents any new language from taking off, since a comprehensive library ecosystem is essential for language success.
Escaping “The Mess We’re In”
Several years ago, I embarked on an ambitious proof-of-concept project called Resequence that would act as unification for most of the tools that we use to write programs. The idea was sparked by Joe Armstrong’s (of Erlang fame) talk “The Mess We’re In” at Strange Loop 2014, and his earlier post on the Erlang mailing list. At that point I had an entire summer to work full time on the project. Unfortunately health issues prevented me from working on the project that summer, and I haven’t had much time to directly work on it since. Ultimately, the project was too ambitious for the timeframe that I had, and the amount of work would realistically require a large team of developers. At this point the project is vaporware. The motivation of this post is to explore the design space of what I want to work on.
The core of Resequence is a fine-grained project repository stored in a distributed hash table. The system is fine-grained since the atomic unit of information is a function or type definition. Within a compiler, a program is typically represented as an abstract syntax tree (AST). Typically the AST is hidden from the programmer, with the exception of languages that support metaprogramming. In the larger view of a program, function ASTs are hooked together into a directed graph dependency structure known as a call graph. Resequence understands that programs are represented as ASTs and call graphs, which enables a large number of exciting potential features.
What’s in a Name?
Storing anything in a distributed hash table requires a hashing function. Since we’re representing programs as directed graphs, we need a hashing function that can hash directed graphs. This hashing function has proved challenging since there doesn’t seem to be an existing algorithm that can be used. Getting the hashing right is tricky, so this is mostly what I’ve been thinking about. The hash of a specific node in a call graph should depend on all the nodes reachable from that node. So if a library that a function depends on changes, the hash of the original function should change. After all, that change might have impacted the behaviour of the dependant callers.
AST Example by Abloomfi from Wikipedia Commons

The abstract syntax tree picture needs to be rectified with the call graph representation. In programming languages, ASTs are usually represented by an expression type, which may recursively contain other expressions. Instead of just referring to the expression type directly, we instead use a parameterized wrapper type. This wrapper type can be split into three different cases:
- A pass-through case which has no impact on the AST structure
- A splice case which indicates that the AST at the referenced hash should be directly spliced into this location. This is useful for representing modules, which are directly composed of functions and types.
- A reference case (also with a hash), which broadly represents a reference dependancy between program structures.
Most programming languges provide code organization systems, often called modules or namespaces. When a function is placed into a module, the function obtains context from the enclosing module. This context may include things like aliases created by imports from other modules. Obviously when a programmer is working with code in an editor, they will not want to be dealing with hash codes when calling other functions. Since the context often influences the name of a function being called, modeling this context is another key ingredient of Resequence. At this point I am not sure how to deal with the context, so this is something that will need more work.
Naming in programs are used as human-understandable identifiers for other parts of the programs. For most situations, the actual name is completely irrelevant to program behaviour. In lambda calculus, this problem is solved by using De Bruijn indices, which eliminates names of variables and replaces them with natural numbers (the process is a sort of expression cannonization). Doing a similar such operations on more complex programming languages is challenging but not impossible. Whether or not Resequence should eliminate names is a design choice that needs to be made.
De Bruijn indices in lambda calculus

There are situations where names influence program behaviour. Program behaviour is influenced when the notion of structural equality is used instead of referential equality. For example, OCaml uses row type polymorphism for object types. In this case, the name of the fields dramatically influence the type checker and overall program flow, so getting rid of the field names seems difficult or potentially impossible.
Smarter Tools
Today is our quarterly reminder that Linus gave us a completely distributed VCS, so we stored all of our repos in a single point of failure.
— Gary Bernhardt (@garybernhardt) August 15, 2013
If we store programs as ASTs and graphs, the tools we use can be a lot smarter since they understand program structure. I have organized potential tools into a list:
- Version control is an obvious easy target. Resequence would store code in a distributed way, wheras Git repositories are usually stored in a centralized location.
- Dependency and package management, as I discussed previously.
- Code search engines. Haskell has a search engine called Hoogle, which feels almost magical. If you think of a type of a useful function, you can just throw it into Hoogle and get back libraries that have what you need. Sourcegraph is putting a lot of work into similar systems for other languages.
- Distributing a program is as easy as providing the hash code of the main function. All the required dependencies can pulled in automatically. Multiple versions of the same library pose no problems since the system internally uses hash codes.
- Contributing to open source is as easy as writing a single function. A community voting, commenting and curation system all seems possible.
- If one of your libraries causes a crash in your program, the system can automatically submit crash reports to the author of the library. This can be turned on during testing and disabled if that behaviour is undesirable.
- It is currently difficult to modify or fix the code of dependencies. Resequence remedies this problem since the atomic unit of organization is more fine-grained.
- While the code is running, it can occasionally check the repository for updated versions of code. If a new version is detected it can be automatically hot-swapped in. Alternatively, it can prompt the programmer, asking whether it should upgrade.
- Function shadowing: a shadow version of code can be loaded alongside the current code. When a function in the current code is called, the shadow version of the code is run on the same input. The results of the two versions are compared, if they differ the results are recorded. Shadows can be automatically created when an updated version of a function is available in the repository. This seems like an interesting use case for testing new program versions.
- Intelligent autocomplete that attempts to autocomplete an entire function while the programmer is typing by searching the code repository.
- Services can advertise what APIs they provide by listing the hashes of the functions they provide upon request. If an API function changes the programmer can be notified since the hash of the API changes. If an API breaks or shuts down, the system can attempt to automatically discover new APIs that provides the needed functionality.
- Use of machine learning to automatically assemble pipelines of functions that transform the output to a desired target. The algorithm can examine already existing code examples/pipelines of functions and metadata associated with each function to suggest a series of functions to use.
- Applying machine learning to programming language problems in genral is much easier.
- Voting on output: instead of using a single function, the system automatically assembles a group of functions, all of which are run on the same input. Each function gives its results, and the results with the most votes is the final output.
Relaxing at Project Boundaries
So far I’ve been discussing a system that is very tightly coupled - a program that you install always uses the dependencies that the developer intended. One of the advantages of dynamic linking is that packages with security flaws can be upgraded independantly of other packages. Recovering this behaviour seems challenging. One possible solution is to define project boundaries as first class features, and then provide coupling across boundaries using names.
The Cambrian Explosion
The behaviour of programming languages can be specified with mathematical precision by using a variety of semantic systems and typing rules. Generally these rules can be specified in only a few pages, depending on language complexity. If we can encode these rules in a programming language, then maybe we can make a system which will automatically generate an interpreter, compiler, and debugger for any potential language that we want to write. Research into this area is currently underway at universities and corporate labs (Graal & Truffle).
The potential for this type of system is huge. Suddenly a new language can be written in a matter of days instead of months or years. If you can further specify rules for data conversion across language boundaries, then embedding languages inside of each other is both possible and convenient. If you can automatically generate a transpiler between languages, then using a library written in another language is no problem.
There are already some platforms (known as language workbenches) that can do this sort of thing: JetBrains MPS, Xtext, and Intentional Software. Unfortunately the sandbox for these types of systems are pretty restrictive. For example, if you want to use a type system different from what MPS provides, you’re out of luck. Perhaps there is a way to extend MPS, but the documenation is so poor that I can’t figure out how to use it.
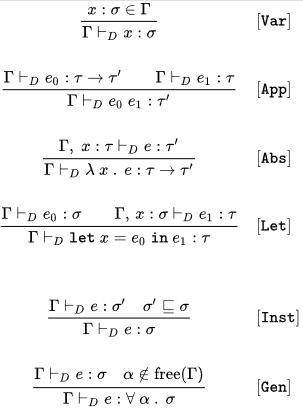
Rules for a Hindley Milner type system
What’s Old is New
The Resequence idea did not develop inside a vacuum. For several years now, I have watched as tools have slowly moved towards this model. The technologies are currently disparate, and nobody has made an attempt to unify their use.
Here are some related interesting miscellaneous links:
- Microsoft’s Intentional Programming demo. This video is worth a watch.
- IPFS: A distributed hash table system. This could potentially be modified to store directed graphs.
- The Unison Programming Platform
- Isomorf: a projectional editor platform
- NixOS, which fixes package dependency problems at the package level.
Moving Forward
A lot of work needs to be completed to realize the fully proposed system. If you’re interested in the project, feel free to post on the comments below. If you represent a company that is interested in working on this type of system, feel free to send an email to caleb.helbling@yahoo.com. I think that any company that creates such a system will have a big advantage in future developer mindshare.